So, wie versprochen, hier nun ein paar meiner Eindrücke von der diesjährigen EuroVis in Swansea, Wales.
Zunächst einmal zum Ort. Wales bietet wunderschöne Landschaften und hat in der Woche der EuroVis mit untypisch schönem Wetter geglänzt. Zumindest haben mir auch mehrere lokal Ansässige bestätigt, dass so viel Sonne und so wenig Regen nicht normal seien. Mir soll es recht sein. Ich hatte meinen Spaß. Für die Woche hatte ich mich in einem kleinen familiengeführten Bed&Breakfast eingemietet. Auch das war eine gute Entscheidung. Mein Zimmer war sauber und gut ausgestattet. Sicherlich nicht Top-Klasse, was auch immer das heißen mag, aber meine Gastgeber waren super freundlich und ich hatte das Gefühl willkommen zu sein. Einziger Wermutstropfen, die Reise: Swansea liegt wirklich weit weg. Und beim Buchen der Reise hat irgendwer auch eher nicht an Komfort gedacht. So verbrachte ich den Pfingstsonntag und den darauf folgenden Samstag jeweils in einer Straßenbahn, zwei Zügen, zwei Flugzeugen, einem Bus, zwei britischen Zügen (mit Verspätung), und einem Taxi. Gegen lange Reisen habe ich nichts. Aber zwischendurch acht Mal umsteigen zu müssen ist ätzend.
Nun zur Konferenz selber. Die Konferenz war auf der Uni in Swansea in vier Räume in drei Gebäuden verteilt. Aufgrund der großen Anzahl an Teilnehmer war das wohl nicht anders zu organisieren. Aber dennoch war das etwas anstrengend.
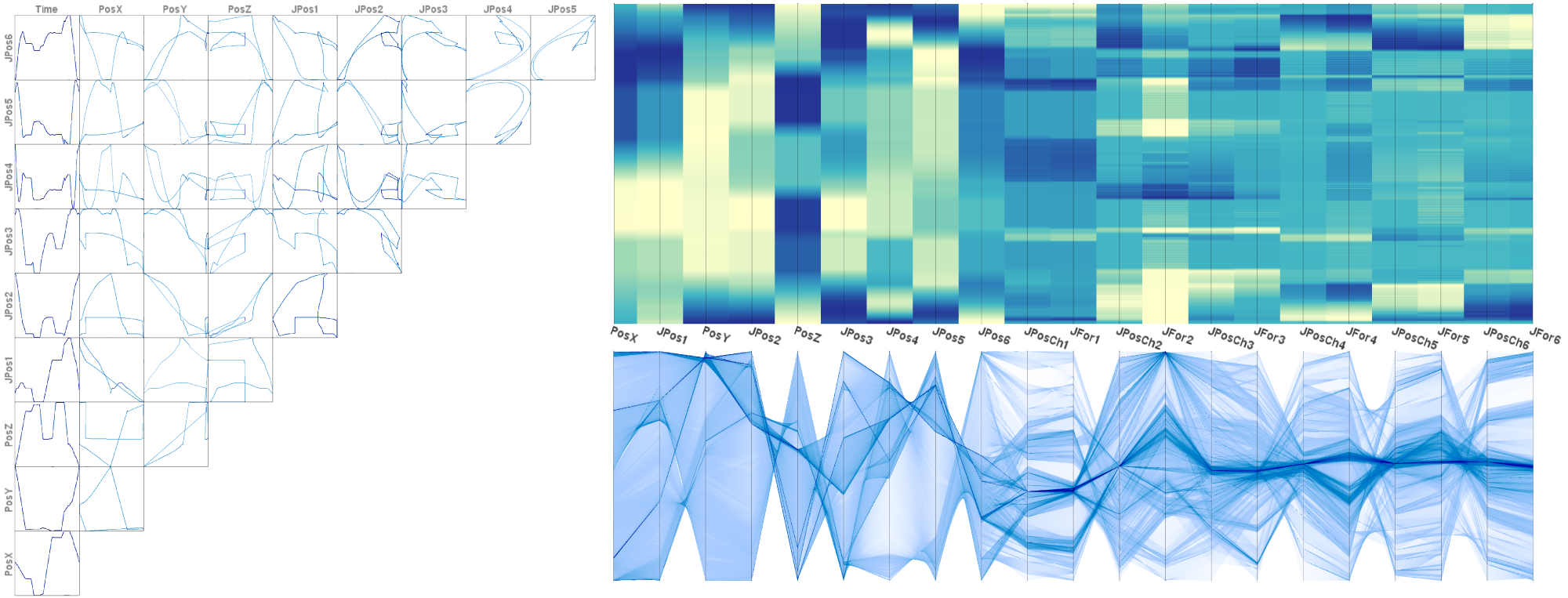
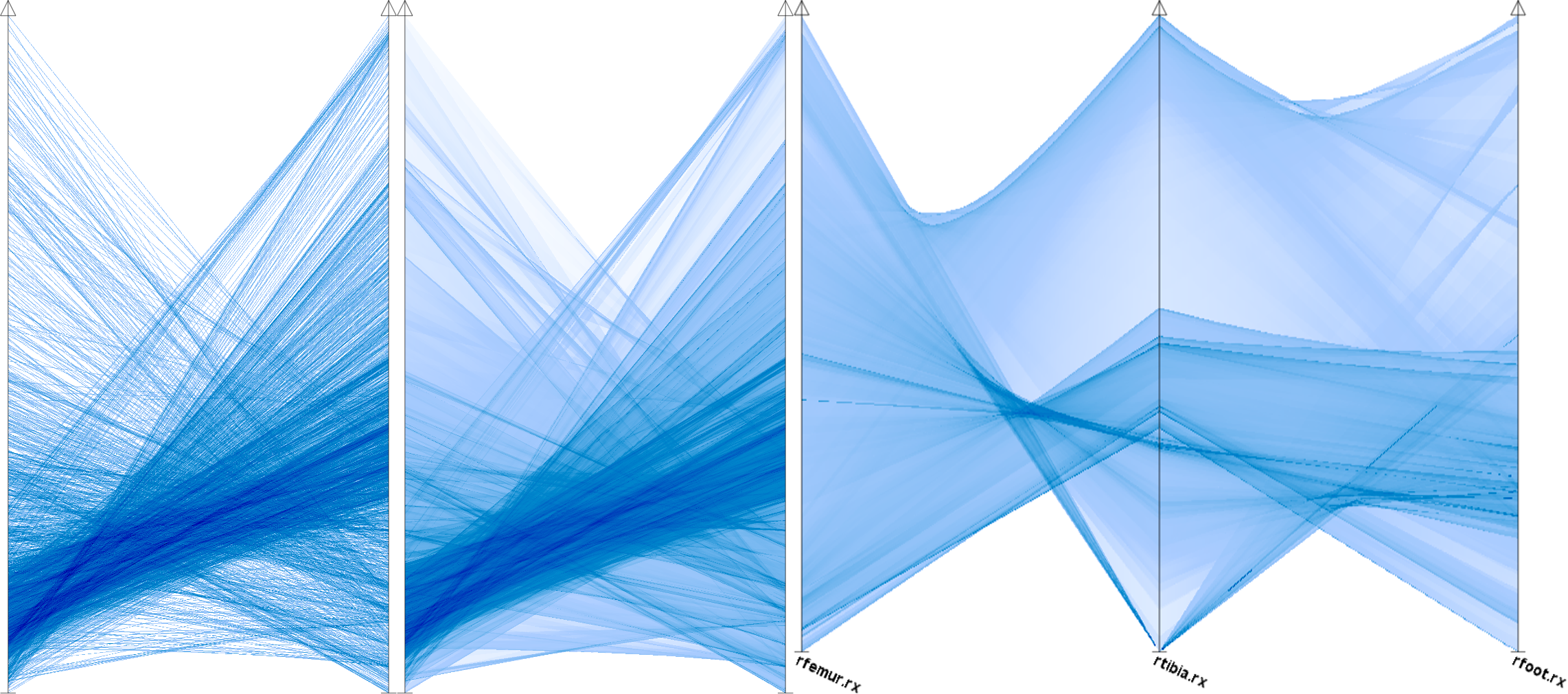
Vor der Haupt-Konferenz kamen einige kleiner Workshops, und obwohl ich im Programm Committee der EnvirVis 2014 bin, dem Workshop zu „Visualization in Environmental Sciences“, habe ich die meisten Sessions die EGPGV besucht, den Eurographics Working Group zu Parallel Graphics and Visualization. In der wissenschaftlichen Visualisierung ist „Big Data“ gerade in aller Munde und entsprechend fand ich diese Vorträge ganz interessant, vor allem die Keynote von Valerio Pascucci. Die restlichen Präsentationen waren durchschnittlich gut. Eine schöne Sache, wenn auch von der Idee her nicht besonders neu, war die Arbeit „Freeprocessing Transparent In Situ Visualization Via Data Interception“ von Thomas Fogal et al.. Preloading for the win. :-) Aber es ist ein guter Ansatz der sicherlich nützlich sein kann.
Auf der Hauptkonferenz gab es viel zu sehen. Wie immer, die Vorträge waren durchschnittlich gut. Wenn ich das so schreibe, übrigens, dann meine ich damit, dass die Vorträge nicht bahnbrechend sind, aber man gut zuhören und meist auch folgen kann. Die großen Konferenzen behaupten immer, einen höheren Qualitätsstandard halten zu können als die kleineren Workshops. Meine Meinung dazu ist eher so, dass die großen Konferenzen 95% gute Vorträge habe und nur ganz wenige die gar nichts taugen. Die kleineren Konferenzen haben hier vielleicht eher ein Verhältnis von 2/3 zu 1/3 was gute und schlechte Arbeiten betrifft. Aber zwischen den guten Vorträgen auf kleinen und auf großen Konferenzen gibt es meiner Meinung nach keine Qualitätsunterschiede. Zwei aus meiner Sicht nette Vorträge waren „Fast RBF Volume Ray Casting on Multicore and Many-Core CPUs“ von Arron Knoll et al. und „Sparse Representation and Visualization for Direct Numerical Simulation of Premixed Combution“ von Timo Oster et al.. Der Capstone-Vortrag von John Stasko war auch unterhaltsam.
Was aber auf der diesjährigen EuroVis wirklich geglänzt hat, das waren die STAR-Tracks. STARs sind State-of-the-art-reports, also Überblicksartikel über ein begrenztes Teilgebiet der Forschung. Gute Stars sind pures Gold wert und sind ein idealer Startpunkt um sich in ein Teilgebiet einzuarbeiten. Dieses Jahr gab die EuroVis zum ersten Mal einen Call für STARs aus und hat diese mit ihrem eigenen Track besonders in Rampenlicht gebracht. Völlig zurecht! Dadurch sind einige wirklich gute STARs entstanden und schön präsentiert worden. Ich bin ehrlich begeistert. Besonders gut gefallen hat mir der STAR zu „A Review of Temporal Data Visualizations Based on Space-Time Cube Operations“ von Benjamin Bach et al.. Nicht nur waren die Arbeit selbst und die Präsentation sehr gut, während der Präsentation entstand auch eine lebhafte und konstruktive Diskussion mit mehreren Personen aus dem Publikum, wodurch viele interessante Ideen aufkamen.
Alles in Allem war die EuroVis 2014 eine interessante und lohnenswerte Konferenz. Ich bin zufrieden.