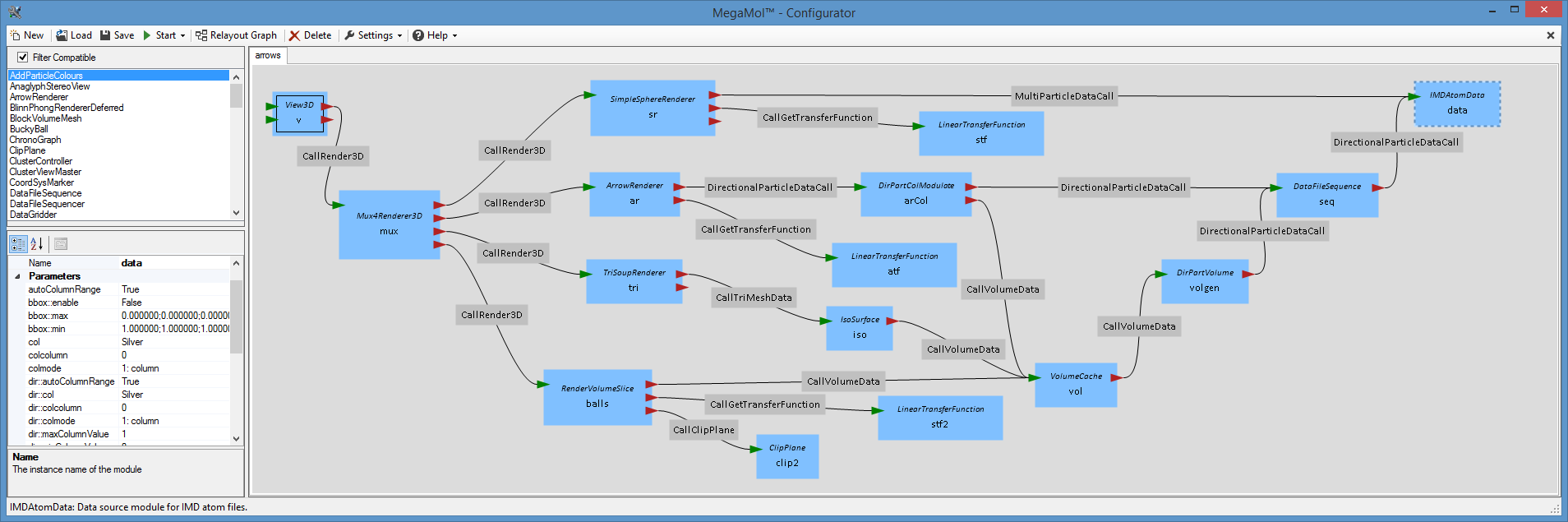
MegaMol™ mit Plugin-Plugin-Abhängigkeiten

Dieser Artikel präsentiert die Details zu Plugin-Plugin-Abhängigkeiten in MegaMol™. Als Hauptszenario nutzt ein Plugin (oder mehrere) exportierte Call-Klassen eine anderen Plugins (und nicht des MegaMol™-Cores).
Tatsächlich wurde am MegaMol™-Core nichts geändert. Die Plugin-Plugin-Abhängigkeiten funktionierten bereits größtenteils. Die Einschränkungen und im Besonderen die Probleme im Fehlerfall sind unten beschrieben.
Testproject: interplugin_test
Dieses Projekt hat zwei Plugins:
https://bitbucket.org/MegaMolDev/megamol_interplugin_test
Plugin A exportiert 2 Module und 1 Call.
Plugin B exportiert ein Modul, welches aber den Call aus Plugin A nutzt.
Export des Call-Header
Normalerweise werden Module und Calls nur über ihrer Metadaten-Description exportiert, als Teil der Implementierung in „plugin_instance“. Diese Metadaten reichen dem MegaMol™-Core um die Module und Calls zur Laufzeit zu instanziieren. Die Klassen selbst werden üblicherweise nicht direkt exportiert.
Wenn wir nun allerdings einen Klasse, einen Call, in einem anderen Plugin zur Compile-Zeit nutzen wollen, dann muss diese Klasse exportiert sein. Zunächst muss der Header der Klasse im Ordner der öffentlichen Header des exportierenden Plugins liegen. Typischerweise sieht das so aus wie im Demoprojekt: „./a/include/interplugin_test_a/IplgDemoCall.h“ Ich empfehle auch die Headerdatei im Visual Studio Solution Explorer in den Filter “Public Header Files” zu legen um hier konsistent zu sein.
Zusätzlich muss die Klasse noch exportiert werden. Das geschieht mit dem API-Macro des Plugins: z. B. „INTERPLUGIN_TEST_A_API”, welches in Haupt-Header des Plugins definiert ist, z. B. „interplugin_test_a/interplugin_test_a.h“
Natürlich müssen die Metadaten-Descriptions des Calls trotzdem nach wie vor in der „plugin_instance“ exportiert werden (vglf. „interplugin_test_a.cpp“ Zeile 51).
Calls in einem anderen Plugin einsetzen
Um den Call nun in einem anderen Plugin zu nutzen muss dieses prinzipiell nur gegen das exportierende Plugin linken. Dem Demoprojekt folgend nennen wir das exportierende Plugin A und das nutzende Plugin B.
Zunächst sind beides einfach nur Bibliotheken, und A ist eine Abhängigkeit für B. Für Visual Studio empfehle ich das Skript „configure.win.pl“ und die Datei „ExtLibs.props.input“ anzupassen, als würde man irgendeine andere Drittherstellerbibliothek hinzufügen. Im Demoprojekt ist der Pfad von Plugin A in „ExtLibs.props.input“ hardgecoded. Anschließend kann das neue User-Macro in den Projekteinstellungen genutzt werden:
- C/C++ > General > Additional Include Directories
- Z. B. $(PluginAPath)include\
- Linker > General > Additional Library Directories
- Z. B. $(PluginAPath)lib\$(PlatformName)\$(Configuration)\
- Linker > Input > Additional Dependencies
- Z. B. interplugin_test_a.lib
Der Linker nutzt nur die Import-Bibliothek von Plugin A, nicht das kompilierte Plugin selbst.
Nun können auch die öffentlichen Header von Plugin A gefunden und Includet werden, vgl. „./b/src/IplgValueInvertB.cpp“ Zeile 3. Plugin B kann nun die exportierte Klasse ganz normal nutzen, wie jede andere Klasse jeder anderen Bibliothek auch. Keine Sonderbehandlung ist notwendig.
Unter Linux könnte man im „CMakeLists.txt“ auch entsprechende Einstellungen einbauen. Ich habe das nicht gemacht.
Ich installiere alles von MegaMol™ beim Bauen in ein lokales Unterverzeichnis in meinem Home (angegeben durch den Install-Prefix bei den Build-Skripten). Dadurch sind alle Teile MegaMols™ an derselben Stelle. Das betrifft natürlich auch den Core, welcher bereits durch das „CMakeLists.txt“ gefunden wird, und auch Plugin A, welches daher versehentlich gefunden wurde. Daher ist der Include-Pfad für die öffentlichen Header des „installierten“ Plugins bereits bekannt. Außerdem ist es unter Linux nicht notwendig Shared Objects gegen ihre Abhängigkeiten zu linken. Das ist Aufgabe des Runtime-Loaders sämtliche Referenzen aufzulösen. Daher sind weitere Einstellungen zum Bauen des Plugins schlicht nicht notwendig.
Wenn Sie trotzdem das exportierende Plugin explizit finden möchten, beispielsweise, weil es nicht installiert sein sollte, dann müssten Sie am sinnvollsten ein entsprechendes CMake-Find-Skript schreiben und in der „CMakeLists.txt“ des abhängigen Plugins „find_package“ nutzen. Zumindest augenblicklich ist mir das aber egal, da das exportierende Plugin sowieso installiert sein muss, damit alles zur Laufzeit funktionieren kann.
MegaMol™ mit beiden Plugins konfigurieren
In der MegaMol™-Konfigurationsdatei müssen beide Plugins ganz normal angegeben werden, entweder explizit mit ihren Namen (empfohlen) oder per File-Globbing. Sie sollten aber die Anhängigkeiten beachten und die Plugins in der richtigen Reihenfolge laden, z. B. Plugin A sollte vor Plugin B geladen werden. Technisch ist es aber egal.
Beide Plugins, alle Plugins, sind im Prinzip nur Dlls. Wird Plugin B zuerst geladen, also die Dll, so werden auch alle abhängigen Dlls geladen. Dabei ist auch die Dll Plugin A dabei welche daher in den Speicher geladen wird. Allerdings sind die Metadaten von Plugin A noch nicht in den Core geladen und seine Module und Calls daher noch nicht zur Laufzeit verfügbar. Wird nun das Kommando ausgeführt um Plugin A zu laden, und das Betriebssystem aufgefordert diese Dll zu laden, so befindet diese sich schon im Hauptspeicher. Anschließend werden die Metadaten in den Core geladen und stehen den Factories zur Verfügung.
Warnung vor zyklischen Abhängigkeiten
Zyklische Abhängigkeiten sollten, wie immer, vermieden werden. In der Theorie sollte es möglich sein zyklische Abhängigkeiten aufzulösen. Allerdings, sollten Sie ihren Code in diese Richtung entwickeln, dann empfehle ich dringend ein weiteres Plugin zu starten in dem Sie alle gemeinsam genutzten Klassen auslagern, z. B. Calls.
Laufzeitverhalten wenn abhängige Plugins nicht gefunden wurden
Die Fehlermeldungen des Betriebssystems wenn eine Dll (Plugin) nicht geladen werden kann sind ziemlich nutzlos. (Ich arbeite hier an Verbesserungen, aber das ist weit nicht so einfach wie man denken würde.) Normalerweise sagt die Fehlermeldung nur, dass die Dll nicht geladen werden konnte. Denken Sie also daran, dass diese Fehlermeldung nun auch kommen kann wenn ein Plugin die Plugins nicht laden kann von denen es selbst abhängt. Die Plugin-Abhängigkeiten müssen also sowohl zur Compile-Zeit als auch zur Laufzeit auflösbar sein. Beides löst sich selbst wenn einfach alle Plugins in den gleichen lokalen Ordner „installiert“ werden.
Versionsnummertests
Alle Plugins prüfen zum Zeitpunkt wenn sie geladen werden die Versionsnummern von Core und Vislib. Damit werden Inkonsistenzen zur Laufzeit verhindert. Stellen Sie sich vor, sie bauen den Core und arbeiten dann an ihrem Plugin. Dabei fällt eine Bugt in der Vislib auf und wird von ihnen gefixt. Core und Plugin würden nun unterschiedliche Vislibs benutzt und nur diese Versionsnummerprüfungen teilen ihnen mit, dass das eine wirklich schlechte Idee ist.
Nun ersetzen Sie in diesem Szenario die Vislib mit Plugin A. Willkommen in der Hölle. Augenblicklich gibt es keinen Mechanismus um Versionsnummer zwischen Plugins zu überprüfen. (Wahrscheinlich kommt auch keiner vor der Implementierung des berüchtigten „Call-Interface-Redesigns“.) Sie müssen einfach aufpassen!




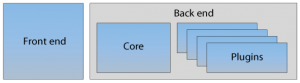 Tatsächlich ist
Tatsächlich ist